Preface
As a follow-up to the storage bloat analysis (https://pqmlmaoxd.github.io/gamedev/analysis/2026/03/15/wuthering-waves-memory-bloat.html), today I want to go deeper into something more contested: why WuWa performs the way it does, and whether the community complaints are actually fair.
Some context before we start: I spent a significant amount of time on this because I genuinely wanted to know whether the frustration was justified — or whether people were blaming developers for problems that go a lot deeper than implementation quality.
This post is not a defense of Kuro Games. It is also not a list of excuses. What it is, I hope, is an honest attempt to explain why the performance situation is considerably more complicated than “the devs didn’t optimize” or “skill issue.”
⚠️ Warning: This post is significantly more technical and academic than the memory bloat article before it. It covers CPU architecture, engine threading models, garbage collection mechanics, and data-oriented programming — if that starts to feel overwhelming, feel free to skip straight to the TL;DR at the end.
The Problem Nobody Can Agree On
I keep seeing the same complaints across Reddit, Discord, and YouTube:
- “Startorch Academy is stuttering badly on my mid/high-end PC — what is going on.”
- “The devs just don’t give AF about optimization, they just keep pushing flashy effects…”
- “Look at AKE, Genshin, RDR2 — they all run smoothly. WuWa can’t do it after 2 years of development?”
What nobody in those threads distinguishes is that “the game performs badly” is actually describing at least two completely separate phenomena — with different root causes, different locations on the map, and different fix timelines.
Pattern A — Stutter while inside the city. Microstutters, unstable frame pacing, FPS that never quite locks. This happens in Startorch Academy, in Septimont, in any dense populated area — regardless of whether you are in combat or just walking. GPU load is unremarkable. The problem is entirely CPU-side.
Pattern B — Hard freeze when leaving the city. This one is harder to forget: you cross the boundary, and the game drops to 0 FPS for 500ms to a few seconds, then recovers completely. Players who have been with WuWa since launch will remember earlier versions where this was severe. It has improved considerably through patches — v3.1’s streaming pipeline optimization made a visible difference — but it has not disappeared entirely.
These two patterns look related because they both happen near dense areas. They are not the same thing:
| Pattern | When it happens | What’s happening | Status |
|---|---|---|---|
| A — City stutter | While inside dense area | GameThread overload from actor count | Engine-level ceiling, unresolved |
| B — Exit freeze | Leaving dense area | Asset streaming flush + V8 GC cycle firing simultaneously | Improved significantly, residual remains |
A third phenomenon exists separately from both of these:
| Also happening | When | Root cause |
|---|---|---|
| Combat FPS drops (mobile) | Dense combat with VFX | GameThread particle saturation → GPU renderer inefficiency cascade |
This post will go through all of these. More importantly, it will try to explain why they are different problems — because that context is what most community analysis misses entirely, and it changes what “optimization” even means here.
1. The Engine’s Fundamental Constraints
1.1 How a Frame Actually Gets Made in UE4
In Unreal Engine 4, every frame flows through three stages, in order:
[GameThread] ──► [RenderThread] ──► [GPU]
The GameThread is where everything that makes the game a game happens: actor updates, physics simulation, AI decisions, animation state machines, particle system tick updates, collision detection, scripting logic — all of it. Every frame. In sequence. On one thread.
When the GameThread finishes, it hands a list of rendering commands to the RenderThread. The RenderThread prepares those commands for the GPU. And here is the critical part: the two threads synchronize at the end of each frame. Neither can start the next frame until both are done with the current one.
From Epic’s own documentation:
“In Unreal Engine 4 (UE4), the entire renderer operates in its own thread that is a frame or two behind the game thread.” “The game thread inserts the command into the rendering command queue… RHI functions can only be called from the rendering thread.”
Source: https://dev.epicgames.com/documentation/unreal-engine/threaded-rendering-in-unreal-engine
In simple terms: if the GameThread is slow, the RenderThread waits. The GPU idles. You get a frame spike. It doesn’t matter how fast your GPU is — it has to wait for the GameThread to finish feeding it work.
Think of it like a restaurant kitchen where every order — no matter how simple — must be personally reviewed and signed off by the head chef before it goes out. The kitchen has 16 sous chefs standing ready. But every ticket still waits for the head chef’s signature. More sous chefs don’t help. A faster head chef helps a little. The bottleneck is the process, not the people.
In UE4, the GameThread is the head chef. Every piece of game logic needs its sign-off every frame, in sequence, before anything moves forward.
The diagnostic command stat unit in UE4 breaks out Game, Draw, and GPU times separately. When Frame time ≈ Game time, the bottleneck is the GameThread. That is where WuWa consistently ends up in dense areas.
1.2 Why Your 6 or 8-Core CPU Cannot Fix This
This is the most counterintuitive thing in this post, so I want to be clear about it.
More CPU cores do not help a GameThread bottleneck.
A community member shared their Process Lasso capture while playing in a dense city area — the pattern is immediately recognizable:
[Image: Community Process Lasso screenshot — i7-11700F, WuWa running in city area. Client-Win64-Shipping.exe shows 319 threads spawned, but overall CPU usage reads 31% while the game simultaneously reports 100% responsiveness pressure. The CPU bar graph in the corner shows a heavily skewed distribution — one cluster of cores working hard, the majority near idle.]
Source: https://www.reddit.com/r/WutheringWaves/comments/1p2pwg0/cpu_issue_apparently_the_new_area_is_full/
The machine has plenty of compute capacity. But all the work that determines whether you get a stutter — every NPC behavior tree, every interaction handler, every AI tick, all the scripting logic — is serialized onto one core. 319 threads exist; the engine cannot distribute the work that matters across them.
My own CapFrameX benchmarks confirm what the Process Lasso pattern shows: across two city sessions on i7-12700KF + RTX 5070, CPU max single thread peaked at 97–100% while overall CPU load averaged 40–46%. The aggregate CPU number looks fine. The per-thread story is entirely different.
The vkguide multithreading article describes this exact issue with UE4:
“You will commonly see that Unreal Engine games struggle scaling past 4 cores… A game that has lots of blueprint usage and AI calculations in UE4 will have the Game Thread busy doing work in 1 core, and then every other core in the machine unused.”
Source: https://vkguide.dev/docs/extra-chapter/multithreading/
And from Epic’s own developer documentation:
“By design, many engine APIs and gameplay operations are not thread-safe, so they must be executed on the GameThread… The Game Thread — Central Execution Thread: Coordinates all gameplay logic each frame.” “But multithreading is not always the silver bullet. Some tasks are inherently sequential, and splitting them up might introduce complexity without performance gains.”
Source: https://dev.epicgames.com/community/learning/tutorials/BdmJ/unreal-engine-multithreading-techniques
I captured two benchmark sessions on the same hardware — i7-12700KF + RTX 5070, identical settings: 1080p, settings, ray tracing, DLAA, no frame generation. Two different cities, same question: is the CPU the ceiling?
Huanglong (v1.0 city):
- Average FPS: 40.2 · CPU max thread: 97% · GPU avg: 54%
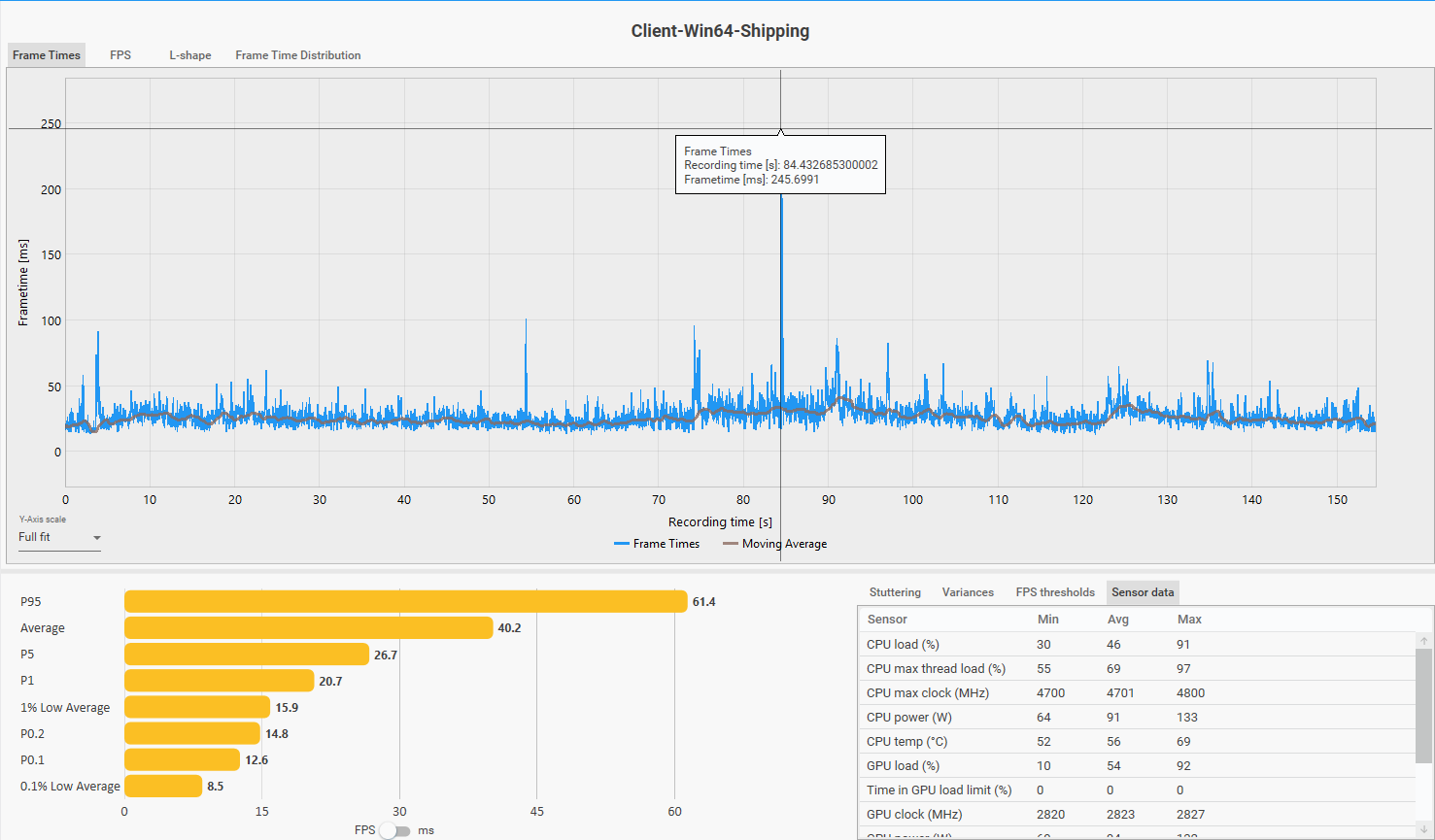 Frame time distribution during Huanglong city traversal. Note the consistent spike pattern — and the 245ms outlier at ~t=85s, deliberately triggered by flying out of the city boundary at maximum speed (Pattern B).
Frame time distribution during Huanglong city traversal. Note the consistent spike pattern — and the 245ms outlier at ~t=85s, deliberately triggered by flying out of the city boundary at maximum speed (Pattern B).
Startorch Academy (v3.0 city):
- Average FPS: 38.5 · CPU max thread: 100% · GPU avg: 58%
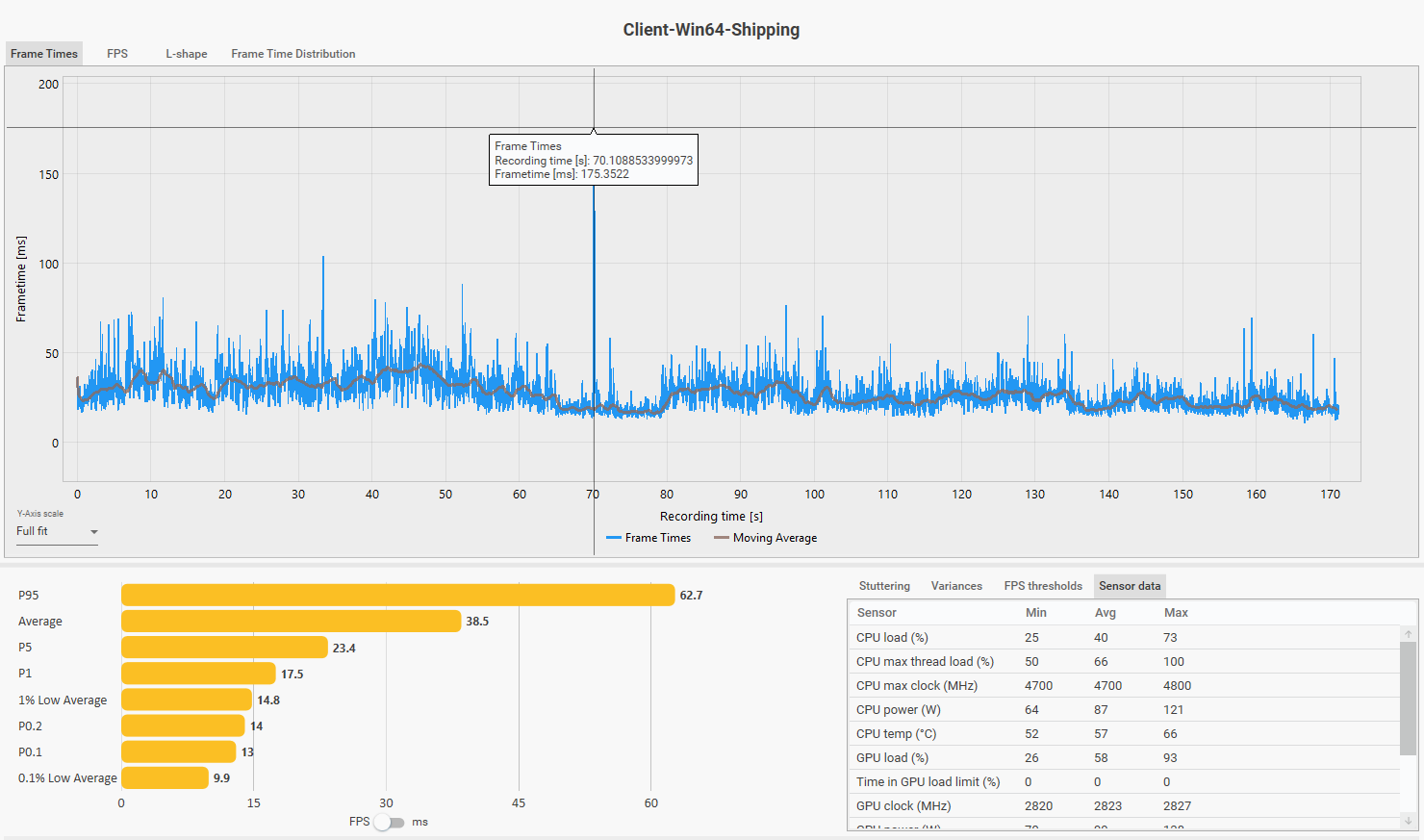 Frame time distribution during Startorch Academy traversal. The 175ms outlier spike (organic, not triggered) occurs with no GPU load correlation — consistent with a V8 GC stop-the-world pause.
Frame time distribution during Startorch Academy traversal. The 175ms outlier spike (organic, not triggered) occurs with no GPU load correlation — consistent with a V8 GC stop-the-world pause.
Two cities. Two sessions. Same answer both times: CPU max thread saturated, GPU underutilized. The sessions corroborate each other — this is not an artifact of one area or one patch. The RTX 5070 averaging 54–58% utilization while the CPU max thread sits at 97–100% is the clearest possible signal. The GPU is waiting. This is just existing in a city — not combat, not a stress test.
Q: So does WuWa need more CPU cores, or a faster clock?
The answer is more nuanced than either. Raw clock speed and IPC (Instructions Per Clock) matter, but for WuWa specifically the most impactful CPU upgrade is often a large L3 cache — and the reason comes directly from the architecture problem described in section 1.3.
In short: the GameThread’s work involves constantly accessing data scattered across RAM. A larger L3 cache keeps more of that data close to the CPU, reducing the stall time on each access. This is why AMD’s X3D CPU — which stack additional L3 cache onto the die — often deliver noticeably smoother WuWa experiences than higher-clocked CPUs with smaller caches, even if their average FPS on paper is lower. A Ryzen 5700X3D may have lower average FPS than an i7-12700KF, but 1% lows and frame consistency in city areas will likely be meaningfully better.
That said: X3D is the best hardware mitigation available, not a cure. It reduces the severity of stutter, but cannot eliminate it — because the root cause is architectural, not a cache size problem that can be fully patched with hardware. The GameThread ceiling, the V8 GC pauses, the OOP pointer-chasing — those all remain. A larger cache makes them hurt less, not disappear.
Practical takeaway: if WuWa stutters and your GPU is below 80% utilization — the upgrade that will help most is a CPU with a large L3 cache, not a new GPU. And calibrate expectations accordingly.
1.3 OOP, Cache Misses, and Why the Engine Fights Itself
There is a deeper problem underneath the GameThread bottleneck. It is not just that everything runs on one thread — it is how that thread accesses data when it runs.
Unreal Engine 4 is built around an Object-Oriented Programming (OOP) model. This is not an informal observation — it is the documented design philosophy of the engine. Epic’s official programming documentation describes UE4 as built around a class hierarchy where UObject is the base for all engine objects and AActor is the base class for everything placeable in a game world, with components attached to actors to define their behavior.
Sources: UE4 Programming Basics · OOP Principles in Unreal Engine
In practice, this means every entity in the game world — every NPC, building facade, particle emitter, tree, physics prop — is an AActor object. Each AActor has a vtable pointer, owns a list of UComponent objects, and those components are heap-allocated individually, sitting wherever the memory allocator placed them at creation time.
In simple terms: every object lives in its own corner of RAM. To update it, the CPU has to go find it.
Imagine the GameThread needs to update 10,000 actors in a single frame — which happens constantly in a scene as dense as Startorch Academy or Septimont City/ Ragunna. The CPU’s work looks like this:
Tick ActorA → follow pointer → find ComponentList → follow pointer → find data
[CPU fetches from RAM: cache miss]
Tick ActorB → follow pointer → find ComponentList → follow pointer → find data
[CPU fetches from RAM: different address, cache miss again]
Tick ActorC → [different address again]
Tick ActorD → [different address again]
...10,000 times
Every single actor tick is a pointer chase through scattered memory. Every time the CPU looks for data that is not already in its L1 or L2 cache, it stalls and waits for main RAM to respond. On a modern CPU, an L1 cache hit costs ~4 cycles. A main memory fetch costs ~200 cycles. In a scene with thousands of actors this penalty accumulates into real, measurable frame time loss — not because the game logic is slow, but because the CPU spends most of its time waiting rather than computing.
A useful mental model: imagine a librarian who needs to look up 10,000 books. In a well-organized library (DOD/ECS), books on the same topic are shelved together — she grabs one section and works through it sequentially. In UE4’s model, each book was shelved wherever it happened to fit when it arrived. She walks across the entire building for every single book. The reading is the same amount of work. The walking is what kills performance.
The L3 cache is a small room next to her desk where she keeps recently-used books nearby. A bigger room (more L3 cache) means fewer trips across the building. This is exactly why X3D processors — with their stacked cache — help specifically with WuWa’s workload where other games don’t see the same benefit.
This is exactly why a large L3 cache matters more for WuWa than raw clock speed. The L3 cache acts as a buffer between the CPU cores and main RAM — the larger it is, the more actor data can sit nearby instead of requiring a full round-trip to RAM. A processor with a 96MB L3 cache (like AMD’s X3D lineup) can keep far more of WuWa’s scattered actor data resident than a processor with 20MB or 30MB, even if the smaller-cache CPU has higher clock speeds. The result in practice: lower average FPS on benchmarks, but meaningfully better 1% lows and frame consistency in city areas — which is exactly where the problem lives.
This is not a problem Kuro introduced. It is a structural consequence of how UE4’s object model works. The engine was designed this way, and there is no mechanism within UE4 to change it without rebuilding the entity system from scratch. A developer in the Unreal Engine community forum observed this limitation directly back in 2018:
“For large scale entity simulation, UE4 will likely not be a great tool choice here. As far as I can tell, none of the large engines are particularly well suited for that type of large scale simulation though.”
Source: https://www.reddit.com/r/unrealengine/comments/9uzkpk/
That last clause — none of the large engines — was accurate at the time. Since then, one of them has changed significantly.
Why Genshin Impact, Arknight Endfield Feels Different
The Genshin comparison comes up constantly in this community, and it is worth addressing properly rather than dismissing.
Genshin Impact runs on Unity. But the reason Genshin handles entity density more gracefully is not simply “Unity is better” — it is the result of MiHoYo (now rebranded as HoYoverse) having a deep, long-term investment in Unity’s architecture, starting well before Genshin was a concept.
HoYoverse’s previous major title, Honkai Impact 3rd, was built on Unity and ran for years at scale. That experience gave them two things Kuro didn’t have when starting WuWa: a team with deep Unity expertise, and time to understand how to push Unity’s architecture toward data-oriented patterns before the hard limits became visible.
Unity’s fundamental design — a component-based system where entities own components rather than inheriting behavior — is architecturally closer to DOD than UE4’s inheritance-heavy AActor model. It is not ECS, but it is a stepping stone. Hoyo had years of Hi3 development to build custom systems, tooling, and institutional knowledge around pushing this architecture toward cache-friendly, parallelism-friendly patterns. By the time Genshin launched, they were working with a heavily customized Unity that reflected a decade of this investment.
Unity only began shipping its official DOTS/ECS framework for production use from 2022 onward — the concept emerged from 2018 research — after Genshin had already launched. Newer titles like Arknights Endfield still use a heavily modified Unity, but develop in an era where official ECS support exists natively in the engine — meaning they can leverage Unity’s own data-oriented infrastructure directly rather than having to build it from scratch the way Hoyo did with Genshin.
OOP approach (UE4 AActor):
Actor_A.Position → address 0x1A3F00 (somewhere in heap)
Actor_B.Position → address 0x7C2104 (completely different location)
Actor_C.Position → address 0x4E8830 (different again)
→ CPU cache: evicted and refilled on every single actor tick
DOD/ECS approach (Unity DOTS / custom):
PositionArray: [ A.pos | B.pos | C.pos | D.pos | E.pos | ... ]
↑ single contiguous memory block
→ CPU loads one cache line, processes several entities, moves to next
→ Cache stays warm for the entire batch
Note: The memory addresses above (0x1A3F00, etc.) are illustrative examples only, not actual values from any real process.
Source: https://unity.com/ecs
Unity’s C# Job System makes the thread-safety implications of this data layout explicit. From Unity’s own documentation:
“To make it easier to write multithreaded code, the Unity C# Job System detects all potential race conditions and protects you from the bugs they can cause.” “The C# Job System solves this by sending each job a copy of the data it needs to operate on, rather than a reference to the data in the main thread.”
Source: https://docs.unity3d.com/2020.1/Documentation/Manual/JobSystemSafetySystem.html
This is the architectural reason why Unity can safely dispatch physics and simulation work to worker threads: each job receives an isolated data copy, eliminating shared-state hazards. UE4’s AActor graph has no equivalent mechanism — actors share references, making safe multi-threading on arbitrary game logic nearly impossible without architectural surgery.
The data ownership model also changes what is possible for parallelism. Contiguous component arrays can be handed to worker threads cleanly. UE4’s interconnected object graph cannot. This is part of why Genshin’s systems can distribute work across cores while WuWa’s remain serialized on one thread.
An honest caveat belongs here: Genshin has a significantly lower visual ceiling than WuWa. The trade runs both ways. DOD-friendly architecture comes with real constraints on content authoring and system interaction. Hoyo had years of prior work and a favorable engine foundation to build on. Kuro was building their first open-world 3D project, on an engine whose entity model is fundamentally OOP, without that institutional runway.
There is no ECS or DOD framework in UE4. Unreal Engine 5 does improve the threading situation somewhat — Mass Entity offers limited large-scale entity simulation support, and UE5’s rendering pipeline has better multi-thread utilization than UE4’s — but the fundamental OOP heritage of the engine remains. AActor, UObject, and the component model are deeply embedded in how UE5 works. The ceiling shifts modestly upward with UE5, but does not disappear. WuWa predates UE5 and is not built on it, so this is academic in any case.
2. The Scripting Layer and Its Costs
2.1 What Puerts Is and Why It Exists Here
Somewhere between UE4’s C++ foundation and the gameplay logic you interact with, WuWa has a scripting layer. This is no longer a matter of inference — it is confirmed by direct evidence from the game’s own runtime logs and binary.
Direct evidence — runtime logs:
WuWa writes diagnostic output to Client\Saved\Logs\Client.log on every launch. The following entries appear consistently across multiple log backups (Client-backup-*.log), ruling out a one-time fluke:
[Client.log line 2564] 启动v8 V8ThreadHelper
[Client.log line 2565] PuertsJsEnv: ... v8 version: header-11.8.172.18, lib-11.8.172.18
[Client.log line 2566] LoadModule: Puerts
The game is explicitly initializing a V8 thread helper, loading the Puerts module, and reporting its V8 version at startup. This is as direct as runtime evidence gets without a full profiler.
Direct evidence — binary strings:
String extraction from Client\Binaries\Win64\Client-Win64-Shipping.exe yields the following identifiers embedded in the binary:
Puerts
PuertsJsEnv
typescript
TypeScriptGeneratedClass
KuroPuerts
puerts/*.js
/Game/Aki/TypeScript/... (multiple paths)
The KuroPuerts identifier in particular suggests a Kuro-specific fork or customization of the Puerts framework, not a stock integration.
Datamined configuration evidence:
This is consistent with what the Arikatsu/WutheringWaves_Data repository shows in terms of content pipeline structure:
BinData/level_entity/ ← legacy TypeScript path (present v1.0 onward)
BinData/prefab/ ← legacy TypeScript path (present v1.0 onward)
BinData/level_entity_csharp/ ← new C# path (first appears v2.8)
BinData/prefab_csharp/ ← new C# path (first appears v3.0)
And confirmed in aki_base.csv, the game’s master database manifest:
v1.0 through v2.7: zero entries mentioning "csharp"
v2.8: LevelEntityForCSharpConfig, db_level_entity_csharp.db ← first migration signal
v3.0: PrefabForCSharpConfig, db_prefab_csharp.db ← expanded to prefab system
v3.1–v3.2: same two entries, infrastructure stable
On accessing pak contents:
While Kuro rotates AES keys per release, the community project at https://github.com/ClostroOffi/wuwa-aes-archive maintains an updated archive of keys across versions, making pak content accessible via tools like FModel. Inspection of unpacked assets through this pipeline reveals the ScriptAssemblies directory under Client/Content/Aki/, containing C# runtime assemblies including CSharpScript.dll, Microsoft.CSharp.dll, mscorlib.dll, and numerous System.* assemblies — confirming the C# runtime environment is fully deployed alongside the TypeScript/Puerts layer.
The directories exist. The database entries exist. The log entries confirm active use at runtime. The Puerts/V8 claim is no longer circumstantial — it is directly confirmed.
Q: Why did Kuro choose a TypeScript scripting layer if it affects performance?
Because at the time WuWa’s development was getting started, the priority was development velocity, and a scripting VM layer delivers exactly that.
Kuro’s previous major project was Punishing: Gray Raven — built on Unity, not UE4. Shifting to Unreal Engine for WuWa meant the team was already navigating an unfamiliar engine. A scripting layer like Puerts addresses a real practical problem: game designers and gameplay engineers can write and iterate on logic in TypeScript without touching C++ or rebuilding the engine. This matters more than it sounds — native C++ development means recompiling the entire source tree for every debug iteration or new function implementation, which is extremely time-consuming on a large project. Hot reload works. Iteration cycles are shorter. The cost is runtime performance at scale — but that cost is invisible early in development when the game is small.
This is the classic live-service bootstrap tradeoff: buy development velocity now, pay the performance cost later. The engineering team almost certainly understood the risk — a scripting VM accumulating GC pressure at scale is not an obscure edge case. But when velocity is non-negotiable and the alternative is slower iteration on an unfamiliar engine, this tradeoff becomes a forced choice, not a mistake. The debt was knowingly taken on. The migration is the repayment.
2.2 The V8 GC Problem — and Pattern B
V8 has two garbage collectors running in tandem. The Minor GC (Scavenger) handles short-lived objects in the young generation — cheap, frequent, mostly invisible. The problem is the Major GC (Mark-Compact), which runs when long-lived objects have accumulated enough to fill the old generation heap.
The default approach, as V8’s own engineering blog describes it:
“A straight-forward approach is to pause JavaScript execution and perform each of these tasks in sequence on the main thread. This can cause jank and latency issues on the main thread, as well as reduced program throughput.”
Source: https://v8.dev/blog/trash-talk
The blog also identifies the specific scenario that makes major GC expensive — exactly the scenario WuWa creates when transitioning from a dense area to open world:
“One potential weakness of a garbage collector which copies surviving objects is that when we allocate a lot of long-living objects, we pay a high cost to copy these objects.”
Source: https://v8.dev/blog/trash-talk
In Startorch Academy or Septimont, JavaScript objects are being created constantly: NPC behavior trees, quest trigger states, building interaction handlers, UI update callbacks. Many survive long enough to be promoted to the old generation heap. When the player leaves the area, those objects become unreachable — but V8 doesn’t know that until the major GC runs.
Think of V8’s garbage collector like a cleaning crew that only comes when called — but when they arrive, they lock the entire building until they’re done. While you’re inside Startorch Academy, clutter accumulates everywhere (an object created for every NPC tick, every quest state update, every interaction). When you walk out, the crew decides now is the time to clean. Everything freezes until they finish, then resumes normally.
The v3.1 streaming update improved how quickly the building empties out when you leave. It didn’t change how the cleaning crew operates. The TS→C# migration is what replaces the cleaning crew itself with one that works incrementally — no lockout required.
This is the mechanism behind Pattern B — the hard freeze when leaving a city or when a large volume of geometry is unloaded at once. The trigger is not limited to city boundaries specifically; any transition where a large pak unload and accumulated GC pressure coincide can produce the same event. Dense city exits are just the most consistent and predictable trigger. It is a compound event:
Player crosses city boundary
│
├─► UE4 asset streaming: unload city pak data
│ Memory deallocation, I/O flush
│ → Streaming spike
│
└─► V8 major GC: heap has been filling
during entire city visit
→ Stop-the-world pause fires at transition
Both simultaneously → 0 FPS freeze 500ms–2s
Modern V8 (the “Orinoco” collector) has improved this with concurrent collection, but acknowledges the limits:
“The advantage here is that the main thread is totally free to execute JavaScript — although there is minor overhead due to some synchronization with helper threads.”
Source: https://v8.dev/blog/trash-talk
Even with Orinoco, the major GC cycle cannot be fully offloaded. In a game engine where the GameThread is already under city load, the compound timing of streaming flush and GC cycle is what produced the severe 0 FPS freezes that long-time players remember.
Why Pattern B has improved but not disappeared: Kuro’s v3.1 streaming pipeline update (“updated the loading pipeline and accelerating data streaming”) addressed the asset streaming component of the compound event. The GC component remains — because that requires migrating the scripting layer away from V8, which is precisely what the TS→C# migration targets. The partial improvement is exactly what you would expect from fixing one of two concurrent causes.
This is the spike that appears with no corresponding GPU load change, no temperature change, nothing on screen to explain it.
I have two benchmark captures that together tell this story clearly.
Startorch Academy session — traversal including a motorbike exit from the academy toward the open world. Worst single frame: 175ms, against a P99.9 of 77ms. That outlier sits far outside the normal distribution tail. At 58% average GPU utilization, the GPU was not the source of a 175ms pause. The profile is consistent with a V8 major GC stop-the-world cycle firing at the area transition.
Huanglong session — same hardware, same settings. During this session, I deliberately flew out of the city boundary at maximum speed using the glider. Worst single frame: 245ms. This was not an organic stutter — it was a controlled trigger of Pattern B. The faster and more abrupt the boundary crossing, the more severe the compound event: streaming flush and GC fire simultaneously with less time between them to stagger the load.
The two numbers together are useful. 175ms organic (Startorch) vs 245ms deliberate rapid exit (Huanglong) shows both the floor and the ceiling of Pattern B severity. Normal traversal produces the 175ms case. Aggressive boundary crossing produces the 245ms case. Earlier versions of the game, before v3.1’s streaming pipeline improvements, likely produced even higher values because the streaming flush component was larger.
Caveat on both spikes: I cannot confirm these are V8 GC events without scripting VM profiler access. The pause profile, magnitude, and absence of GPU correlation are consistent with V8 major GC behavior. I am calling this inferred, not confirmed.
2.3 The Migration and What It Actually Fixes
The TS→C# migration is not a performance patch. It is an architectural foundation change.
C#’s garbage collector — in modern .NET runtimes — uses incremental, concurrent collection rather than stop-the-world freezes. It spreads GC work across multiple frames. Worst-case pauses drop from hundreds of milliseconds to single digits.
What the migration does not fix: the GameThread single-thread ceiling. UE4’s threading architecture will still serialize all game logic on one core. Even after a complete migration, WuWa will still hit the same UE4 scalability wall in dense scenes.
What the migration does fix: removes the scripting VM’s contribution to the worst-case frame time spikes. The 175ms outlier events — those become dramatically less severe or disappear entirely.
| TypeScript (V8) | C# (managed runtime) | |
|---|---|---|
| GC model | Stop-the-world major cycles | Incremental, concurrent |
| Worst-case GC pause | 100–500ms | <10ms typical |
| Per-patch debt growth | Accumulates (every new system adds heap pressure) | Substantially reduced |
| Interop with UE4 | Through V8 bridge | More direct |
The migration also compounds. Every new content system built on the C# path costs less in GC pressure than it would have on V8. The ROI grows with every patch. This is why the migration is worth doing during an active live-service cycle even though players will never see it on a patch note.
The project scale data from the datamine illustrates what they were up against:
| Version | Total files | BinData dirs |
|---|---|---|
| v1.0 | 1,264 | 228 |
| v2.0 | 1,442 | 266 |
| v2.7 | 1,903 | 337 |
| v3.2 | 2,292 | 402 |
The content database grew 81% from launch before the C# migration infrastructure was even scaffolded. Every entity, quest trigger, and prefab added during that period ran through the V8 path. The migration is catching up to nearly three years of accumulated scripting debt.
3. The Context: What Other Games Tell Us
3.1 Hogwarts Legacy: The Same Disease, Different Patient
If you want to understand whether WuWa’s stutter problems are a Kuro problem or a UE4 problem, Hogwarts Legacy is the cleanest data point available.
It runs on UE 4.27. It was made by Avalanche Software with a Warner Bros. budget. And it shipped with some of the most documented PC performance issues of any recent major release — the pattern identical to WuWa:
- CPU-bound specifically in dense areas (Hogsmeade, populated castle sections) while open areas run fine
- GPU underutilized relative to the stutter being experienced
- Single-core CPU frequency matters; adding more cores does not help
A player with a Ryzen 9 5900X and RTX 4090 — one of the stronger gaming setups available — documented the problem directly in a Steam thread:
“5900x with 4090 here. I’m gaming at 4K. If I don’t use frame generation, I can hit 90–99% GPU utilization with 30–40% CPU utilization but the framerate is trash (50fps to 70fps).”
Source: https://steamcommunity.com/app/990080/discussions/0/3824161508141330042/
High GPU load, middling CPU overall load, bad framerate. The same shape as WuWa’s profile. And from a different thread, someone who had figured out the actual cause:
“Its only CPU limited because the engine doesn’t scale to more than a core or 2 so a CPU with more cores isn’t going to help, its single core performance (IPC) it wants and needs. If the engine scaled to 8 cores we wouldn’t see a CPU limitation.”
Source: https://steamcommunity.com/app/990080/discussions/0/3789254716328881575/
That second quote comes from a player — not a developer — who arrived at the correct technical diagnosis through observation. It describes UE4’s GameThread architecture more accurately than most technical write-ups.
This is not coincidence. It is the same engine, the same threading model, the same single-thread ceiling — on a project with far greater resources than WuWa had at launch. The lesson is not that Kuro failed to solve a problem other studios successfully solved. No UE4 open-world game has solved it.
Q: So why did Kuro choose UE4 if it has these limitations?
Because they wanted to build a next-generation gacha game, and in 2019–2020, UE4 was the most practical foundation for that ambition. UE5 did not yet exist. Unity’s DOTS/ECS was not production-stable at this scale. Building a custom engine from scratch — as CD Projekt did with REDEngine, or Rockstar with RAGE — requires years of dedicated R&D that simply wasn’t available.
UE4 offered mature tooling, a large hiring pool, and enough flexibility to be pushed hard. And to Kuro’s credit, the version of UE4 they shipped is not a stock build — it incorporates custom modifications including rendering technology that mirrors features from UE5’s Lumen system. That kind of deep engine work doesn’t happen by accident. The team that shipped WuWa understood Unreal well enough to modify it at a significant level.
What was harder to foresee was how badly these specific limitations would surface at WuWa’s scale. In 2020 when development began, open-world UE4 games with comparable ambition were scarce — Tower of Fantasy had just released in 2021, Hogwarts Legacy in 2023. The full picture of what this engine pattern costs in a live-service open-world context at this visual fidelity wasn’t visible yet. Nobody had walked this exact road before. In hindsight the technical debt is clear. At the time it was much less so.
3.2 Gears 5 and Fortnite: The UE4 Exceptions (And Why They Don’t Apply)
Gears 5, made by The Coalition, is frequently cited as the best UE4 implementation. It runs at locked 60fps on consoles, scales cleanly to PC, and has smooth frame times. The reason is directly relevant: it is not an open world. Linear level design allows aggressive pre-baked culling. There is no streaming complexity, no unpredictable actor density, no live-service accumulation. The Coalition designed around UE4’s constraints for a game type that fits them naturally.
Fortnite deserves a mention here as the other commonly cited UE4 exception — and it is genuinely exceptional, because it is made by Epic Games themselves, the developers of Unreal. Having direct access to the engine team, the ability to modify the engine at any depth on any timeline, and institutional knowledge that no external studio can match produces a different class of result. Fortnite is also not an open-world game in the sense WuWa is — its dense city areas and match structure are architecturally different from a persistent open world with thousands of simultaneously ticking actors. But even acknowledging those differences, it is worth noting that the smoothest UE4 experience available comes from the engine’s own creators.
WuWa is neither of these. The game type won’t allow Gears 5’s approach, and Kuro doesn’t have Epic’s internal access.
3.3 Cyberpunk 2077 and RDR2: When People Compare Apples to Custom Engines
Another common community comparison goes like this: “Cyberpunk 2077, Red Dead Redemption 2 looks incredible and runs really stable. Why does WuWa struggle at stuttering?” It is worth addressing this directly, because the comparison fundamentally misunderstands what is being compared.
REDEngine 4 (Cyberpunk) and RAGE (RDR2) do not have the same GameThread problem because they were not built with UE4’s design philosophy — or UE4 at all.
CD Projekt redesigned REDEngine specifically for open-world streaming. Its job system is native to the architecture, not bolted on. Draw call submission distributes across threads. The entity component system was built for this use case from scratch.
RAGE has over twenty years of iteration specifically for dense open-world environments. Rockstar’s streaming system anticipates geometry before the camera reaches it. Memory layout was designed for cache coherency long before the term “data-oriented design” became mainstream.
Comparing WuWa’s frame times to these games is not a fair performance comparison. It is a comparison between a general-purpose engine used for a demanding use case, and custom infrastructure built specifically to handle that use case over many years. Different tools, different constraints, different histories.
4. What Kuro Is Actually Doing
4.1 Patch Performance Improvements
Every patch note that mentions performance optimization is a payment against the technical debt balance. Looking at the official patch notes from v1.2 through v3.2, a pattern emerges — not just that Kuro is working on performance, but what kind of work is being done and how that evolves over time.
The early patches focused on surface-level stability:
v1.2 — “Optimized game performance for select mobile devices.” Targeted, device-specific. No architectural change.
v1.4 — Optimized shader compilation on PC; moved it to title screen to reduce visual glitches during gameplay. Added Auto FPS for Android to prevent overheating. This patch is notable because it addresses one of UE4’s most notorious pain points — in-game shader compilation — and pushes it out of the main gameplay loop.
The middle era (v2.x) shows scope expanding:
v2.0 — “Optimized CPU usage for NPCs, allowing more NPCs to appear on the screen at the same time.” This is a direct GameThread optimization. Kuro is explicitly acknowledging that NPC density has a CPU cost, not a GPU cost — and working on it.
v2.2 — “Optimized the efficiency of the shader compilation process and the hardware resource usage on PC.” Second pass on the shader problem.
v2.8 — The most substantive performance patch in the dataset:
- “GPU load from Ray Tracing and increased frame rates will be reduced”
- “Memory and VRAM usage will be reduced when various types of scenes are being displayed”
Two separate categories of improvement in one patch — rendering overhead and memory pressure simultaneously. This is not a surface fix.
v3.1 — “Optimized the game’s resource loading performance by updating the loading pipeline and accelerating data streaming, to help reduce loading stutter on some PC/mobile devices with lower specs.” Direct address of loading stutter — the symptom category that asset streaming problems produce.
v3.3 preview (April 17, 2026) — The 2nd anniversary version livestream previewed v3.3 content. No specific performance patch notes available at time of writing — this section will be updated when patch notes release on April 30, 2026.
The trajectory is meaningful: from device-specific tweaks in 1.x, to CPU/NPC optimization in 2.0, to RT overhead and memory reduction in 2.8, to streaming pipeline improvements in 3.1. Each payment is incremental. None of it solves the architectural ceiling. But it accumulates.
Two observations worth flagging:
First, v3.1’s streaming pipeline update — “updated the loading pipeline and accelerating data streaming” — is the patch that visibly reduced Pattern B (the hard 0 FPS freeze when leaving cities). Players who have been with the game since 2024 will recognize this. The improvement is real and measurable in daily play. What remains is the GC component of that compound event, which the streaming fix could not address.
Second, v2.8 is a milestone in both directions simultaneously: the most substantive performance optimization patch in the dataset, and the version where LevelEntityForCSharpConfig first appears in aki_base.csv. The surface-level optimizations and the architectural migration began in the same patch. They are not sequential — they are parallel tracks.
4.2 The Migration in Context
The TS→C# migration deserves a specific comparison to the other optimization work that could theoretically be done.
Consider CPU-side culling improvements, VFX LOD authoring, or shader precision tuning. Each of these is a real fix for a real problem. None of them require a new engine. And yet none of them have been fully shipped.
The reason is not that Kuro doesn’t know about them. It is that “technically fixable” and “feasible within a live-service release cadence” are different things.
The engineering team is running on a treadmill. Optimizing deeply means stopping to fix the treadmill — but if the treadmill stops, you fall off. The TS→C# migration is the equivalent of replacing the treadmill’s core components one at a time, while still running, without players noticing the machine is being rebuilt underneath them.
Retrofitting VFX LOD for WuWa’s character skill sets, for example, is not an engineering task. It is a content production task: reopen every existing skill VFX — across 50+ characters with 5–6 skills each — author LOD variants, QA each one for visual regressions on content that is already live, train artists on the new workflow, and enforce it for every future release. That work competes directly with the characters, events, and areas that have to ship in the next six-week window to keep the game viable.
The TS→C# migration gets prioritized over these fixes because it is the one change with compounding infrastructure returns. Every future content addition on the C# path carries less GC risk than it would have on V8. The ROI is exponential, not linear. Shader precision tuning has one-time ROI. The migration’s value grows with every patch.
Kuro is doing this migration in addition to maintaining the six-week content schedule. When it works correctly, players don’t notice. That is the nature of infrastructure work.
4.3 MagicDawn: The Longer Term
MagicDawn is Tencent Games’ internal rendering research team. Their published work from 2025–2026 includes:
- Neural Dynamic GI (CVPR 2026): Neural compression for temporal lightmap sets, enabling dynamic global illumination with dramatically reduced storage and compute overhead
- Gaussian Probe Compression (SIGGRAPH 2025): Light probe compression up to 1:50 ratio with real-time GPU decompression
- Lightmap Compression (Eurographics 2026): 83% storage reduction in UV-space lightmaps with PSNR improvements
Source: https://magicdawnlab.github.io/
This is not “AI ray tracing on Tencent servers.” This is foundational rendering research that reduces GPU overhead for lighting computation — freeing frame budget that currently goes to lighting for other work. Whether and when this integrates into WuWa specifically isn’t confirmed. What it shows is that Tencent is investing in rendering infrastructure at the research level that would benefit a game with WuWa’s visual ambitions.
5. A Response to the Reddit Profiling Analysis
A detailed performance analysis was posted to the WuWa community, based on hardware traces from a Snapdragon 8 Elite device (https://www.reddit.com/r/WutheringWaves/comments/1rtuzc8/wuthering_waves_performance_issues_analysis/). I want to be clear upfront: the data in that post is real and worth taking seriously. The measured numbers — 50% primitive rejection in open world, up to 99% in combat, L1 cache miss rates of 70–100%, FP32 shader dominance — come from actual hardware traces and should not be dismissed.
The issue is with the framing, not the data.
The post treats each GPU-side problem as an independent optimization failure: culling should be better, texture batching should be better, shaders should use lower precision. All of these are individually accurate observations. The conclusion — that none of them require a new engine — is also accurate.
What the post does not explain is why culling fails specifically under combat load.
The 99% trivial rejection rate in combat is not culling code that was written poorly. It is culling code that did not have time to run — because by the time the game reaches the GPU submission step, the GameThread has already consumed its entire frame budget on particle system updates, scripting ticks, and actor physics. There was no time left for culling.
Fixing the culling algorithm while the GameThread is still saturated does not fix the problem. It fixes a symptom. The cascade looks like this:
Root cause: GameThread saturation ← engine architecture
│
▼
Symptom 1: CPU-side culling runs out of time before GPU submission deadline
│
▼
Symptom 2: Unculled geometry submitted → GPU performs trivial rejection
(50% open world, up to 99% combat)
│
▼
Symptom 3: Draw calls jump across unrelated textures → L1/L2 cache thrashed
(L1 miss 70–100%, L2 miss ~45%)
│
▼
Symptom 4: GPU stalls waiting for memory, then waits again next frame
Treating Symptoms 2–4 as independent failures misses that they share a root. The GPU isn’t doing wasted work because someone forgot to write culling code. The GPU is doing wasted work because the code that would have prevented it didn’t get scheduled.
A note on causal attribution: the cascade above represents the most architecturally consistent explanation for the observed data, but it cannot be verified without full profiler access to the codebase. There are at least three plausible hypotheses for the culling failure: (1) GameThread has no time budget left for culling — the engine architecture explanation; (2) the culling algorithm itself is poorly implemented — an implementation quality issue; (3) the culling pipeline is structurally misdesigned for this workload — a hybrid of both. The honest position is that engine constraints and implementation quality are two separate variables whose individual contributions cannot be separated from the outside. Both are present. Their relative weight is unknown. This analysis treats hypothesis (1) as the primary explanation because it is most consistent with the broader data pattern, but readers should weigh that accordingly.
One additional data point worth noting: community engine configs confirm that r.ParallelFrustumCull=1 and r.ParallelOcclusionCull=1 are functional in WuWa’s shipping build — suggesting culling work can be partially offloaded from the GameThread to parallel threads. Whether this meaningfully shifts the bottleneck profile in dense city areas would require profiling to confirm, but their availability indicates the culling pipeline is not entirely GameThread-serialized.
— Flagged by @HtooMyatLin3
The Android Scheduling Dimension
The mobile profiling post also misses a platform-specific amplifier that matters for understanding the mobile experience specifically.
On Android, the Energy-Aware Scheduling (EAS) system manages which physical CPU core each thread runs on, dynamically migrating threads between the “big” (high-performance) and “LITTLE” (efficiency) clusters based on recent load history.
The problem: EAS uses a historical weighted average to decide where to place a thread. If the GameThread has been light for a few frames — say, during a loading transition — EAS may judge it as a light workload and assign it to an efficiency core. Then the scene becomes dense. The GameThread spikes. But the OS scheduler doesn’t react instantaneously: it takes time to recognize the new load level and migrate the thread to the prime core.
During that migration window, the GameThread is doing heavy work on a core not designed for it. The culling budget collapses further. The cascade gets worse.
The Android AOSP documentation acknowledges this problem directly:
“Without the scheduler change to make foreground apps more likely to move to the big CPU cluster, foreground apps may have insufficient CPU capacity to render until the scheduler decided to load balance the thread to a big CPU core.”
Source: https://source.android.com/docs/core/tests/debug/jank_capacity
This dimension does not exist on PC — x86 desktop CPUs are symmetric. Mobile stutter has this additional amplification layer on top of the same GameThread problem. The symptoms look similar; the mechanics are different.
On FP32: The Cross-Platform Constraint
The profiling post suggests transitioning to FP16 shaders as a quick optimization for mobile Adreno GPUs, where FP16 throughput is genuinely 2× faster.
This is accurate for Adreno. It ignores that WuWa runs on Adreno, Mali, Apple GPU, desktop AMD, desktop Nvidia, and Intel integrated graphics simultaneously. FP16 behavior and gain vary significantly across these GPU families. Maintaining separate shader variants per GPU family means larger pak files (the community has a separate ongoing conversation about WuWa’s storage footprint) and QA burden that multiplies with every device class.
The tradeoff is real. It is not as simple as the post implies. Community member @HtooMyatLin3 adds an important hardware-level nuance: FP16 throughput on GTX-series hardware (e.g. GTX 1060) runs at 1:64 ratio vs FP32 — meaning FP16 would be catastrophically slower on that GPU family. Dropping FP16 support for GTX would be required before any meaningful shader precision optimization could ship. By contrast, AMD RX 570 has identical throughput on both FP32 and FP16, so the optimization gap is highly architecture-dependent rather than a simple “switch FP16 on” solution.
The One Genuinely Easy Fix
The post documented r.Streaming.PoolSize = 400 from the Perfetto trace. On flagship mobile devices with 12–16 GB RAM, reserving only 400 MB for texture streaming is directly why L1 and L2 caches get thrashed — textures aren’t loaded into faster memory ahead of time because the pool is too small to hold them.
This is a configuration value. It has no architectural tradeoff. It is the one finding from that analysis that is genuinely addressable without any of the complications I’ve described elsewhere.
On r.Streaming.FullyLoadUsedTextures and r.Streaming.HLODStrategy: These are real UE4 engine cvars — FullyLoadUsedTextures forces all active textures to stream in immediately, HLODStrategy 2 disables HLOD-specific streaming entirely. Community member @HtooMyatLin3 reports that both cvars were usable in older patches (visible in earlier AlteriaX config commits) but are now being set by Kuro via code or console at a higher priority level — confirmed through log analysis — meaning Engine.ini entries are overridden and no longer effective at runtime. This represents a case where an easy fix was available, was being used by the community, and has since been locked down in the shipping build.
6. The Harder Truth
Where Kuro Actually Is
Kuro isn’t doing nothing. They’re also not in a position where they can optimize their way to smooth performance across all hardware tiers. What they’re in is something harder: a local optimal trap — a state where every available move makes something worse.
- If they pause content to do deep optimization work: player engagement drops, revenue drops, the project’s survival is threatened — which removes the budget and rationale for optimization
- If they keep shipping content without optimization work: technical debt compounds, performance degrades, player frustration grows
- If they attempt large architectural refactors: they risk catastrophic regressions in a live system that cannot tolerate them
Every direction has a cost. The current state isn’t laziness. It is the equilibrium that emerges when every alternative is worse.
The TS→C# migration is significant because it is not optimization within this trap — it is an attempt to change the shape of the trap itself. Local search — fixing individual culling issues, tuning shader precision — improves performance incrementally but cannot change the underlying constraints. The scripting migration is a structural change that opens solution space not accessible from the current position.
It will not fix the GameThread ceiling. UE4’s threading model will still limit how much work can be parallelized. But removing V8’s stop-the-world pauses from the frame budget gives the GameThread more headroom, and reduces the severity of the worst-case stutter events. That is a meaningful improvement even if it is not a complete solution.
What “Poorly Optimized” Actually Means — and Why the Comparison Is Harder Than It Looks
When someone says WuWa is poorly optimized, the implicit benchmark is usually one of two things: “Cyberpunk runs smoothly at >=60fps, why doesn’t WuWa?” or “Genshin, AKE is smooth, why isn’t this?”
Both comparisons miss what WuWa is actually trying to do simultaneously.
Consider the full constraint stack Kuro is operating under:
- Open-world game with large, continuously loaded environments
- 3A visual ambition — lighting, geometry complexity, and effect density comparable to high-budget PC titles
- Dense populated cities with hundreds of concurrently ticking NPCs, each with full AI behavior
- Combat-focused design requiring tight input latency, complex VFX, and simultaneous physics — all of which share the same GameThread budget
- Cross-platform — PC, PS5, iOS, Android, Mac — each with different GPU families, memory constraints, and scheduler behaviors
- Wide hardware range from flagship phones to budget Android devices, requiring config tuning that serves everyone
- Live-service 6-week cadence shipping new characters, areas, and systems continuously
- UE4 as foundation — a general-purpose engine not designed for any of these specific requirements in combination
No other game is currently doing all of these things together on UE4. Not Hogwarts Legacy (offline, no mobile, simpler combat). Not Tower of Fantasy (lower visual bar). Not Genshin (different engine, different architecture, lower graphical ceiling). The honest answer to “is WuWa poorly optimized compared to games in the same constraints?” is that there are no games in the same constraints to compare against.
Before concluding that WuWa’s performance is worse than it should be, you need to find another UE4 game that is simultaneously open-world, 3A visual fidelity, live-service at 6-week cadence, combat-heavy with complex VFX, cross-platform from mobile to PC, AND supporting a wide hardware range from budget devices to flagships. Until that comparison exists, the claim that Kuro’s optimization is below some reasonable baseline is not supported.
What we can say is that WuWa is running near the ceiling of what its engine architecture allows, given everything it’s attempting. That ceiling is real, it’s engine-level, and no external team has demonstrated how to escape it in a comparable context.
Cyberpunk runs on REDEngine — purpose-built for open-world performance by a studio that spent a decade constructing it. RDR2 runs on RAGE — over twenty years of iteration for dense open-world environments. These are not performance comparisons. They are comparisons between a general-purpose engine under pressure and custom infrastructure designed specifically to avoid that pressure.
The honest comparison is UE4 vs UE4: Hogwarts Legacy shipped CPU-bound in dense areas with Warner Bros. budget. PUBG — not an open-world game, but relevant as a long-running UE4 title — still produces GameThread stutter after years of work. Tower of Fantasy, the closest genre match, has faced performance complaints throughout its life. No UE4 open-world game has solved this problem. Not one.
One additional layer compounds everything: cross-platform support. WuWa ships on PC, iOS, Android, PS5, and Mac. Every optimization decision, every config value, every shader tradeoff has to work across GPU families from Adreno to Mali to Apple to desktop AMD and Nvidia, across devices from 6GB RAM phones to 64GB workstations. This is a constraint that single-platform games simply do not face, and it makes every “why not just fix X” question significantly harder to answer.
The accurate statement is not “Kuro failed to optimize something other studios got right.” The accurate statement is: hardware is not keeping pace with the technical debt and engine limitations that accumulate when a project of this visual ambition runs on this architecture, in a live-service deployment model that makes deep infrastructure changes nearly impossible.
That is a different diagnosis from “the devs are lazy.” And it points toward very different expectations.
TL;DR
Why WuWa stutters — the short version
The game is bottlenecked at a single CPU thread called the GameThread. Every piece of game logic — NPC AI, physics, scripting, particle updates — has to queue through that one thread, in sequence, every frame. It doesn’t matter how many CPU cores you have. It doesn’t matter how fast your GPU is.
Think of it like a highway with eight lanes — but only one toll booth. All traffic has to merge and pass through that single point before anything can move forward. Add more lanes and the jam doesn’t get better. That toll booth is the GameThread. Startorch Academy has hundreds of NPCs, buildings with active interaction logic, and complex ambient systems all trying to pass through it simultaneously. The thread saturates. Everything waits.
Why can’t they just fix it?
Because the toll booth is part of how Unreal Engine 4 was designed. It’s not a bug Kuro wrote — it’s the architectural foundation that every UE4 game is built on. Hogwarts Legacy has the same problem. So does Tower of Fantasy. No UE4 open-world game has escaped it.
What is Kuro actually doing?
Patching consistently — performance improvements appear in nearly every major update. And quietly migrating the scripting layer from TypeScript (which uses V8’s garbage collector, the cause of the hard freezes when leaving cities) to C# (a runtime with incremental, low-pause GC). That migration is confirmed by runtime logs, binary analysis, and datamine evidence. It’s expensive and invisible to players — and they’re doing it anyway while maintaining a 6-week content schedule.
The bottom line
“Dev lazy” doesn’t explain why Hogwarts Legacy had the same stutter pattern on a Warner Bros. budget. “Engine ceiling + live-service technical debt” does. The claim that Kuro’s optimization is below par requires a comparable game — UE4, open-world, live-service, cross-platform, combat-heavy — to benchmark against. That game doesn’t exist yet.
If you want the full technical breakdown of why each of these things happens at the architecture level — keep reading from the top.
Limitations of This Analysis
This analysis relies on datamined configuration files from Arikatsu/WutheringWaves_Data, personal benchmark captures (CapFrameX, i7-12700KF + RTX 5070 — two sessions: Huanglong and Startorch Academy), community-reported hardware traces, official Unreal Engine documentation, and community profiling data.
On the Puerts/V8 claim: This is now supported by direct evidence. Runtime log files (Client.log and multiple Client-backup-*.log) explicitly record V8 initialization, Puerts module loading, and V8 version strings on every launch. String extraction from Client-Win64-Shipping.exe yields identifiers including Puerts, PuertsJsEnv, KuroPuerts, TypeScriptGeneratedClass, and multiple /Game/Aki/TypeScript/ paths. FModel inspection of pak contents (via the community AES key archive at https://github.com/ClostroOffi/wuwa-aes-archive) reveals the ScriptAssemblies directory containing C# runtime assemblies deployed alongside the Puerts layer. This claim is confirmed, not inferred.
On the C# migration: The infrastructure is confirmed in datamine (aki_base.csv v2.8+, _csharp directories). The ScriptAssemblies pak contents confirm the C# runtime is deployed. Content migration is ongoing — the config files remain partially populated.
The 175ms and 245ms frame spike interpretations as GC pause events are consistent with V8’s documented behavior but cannot be confirmed without scripting VM profiler access. Both spikes are real and measured from hardware data. Their cause is the most technically consistent explanation available given the absence of GPU and thermal correlation.
The causal attribution between GameThread saturation and culling failure (Section 5) represents the most architecturally consistent explanation for the data, but cannot be fully separated from implementation-quality contributions without codebase-level profiler access.
On the customized UE4 build: Community engine config analysis reveals r.Streaming.UsingKuroStreamingPriority — a cvar not present in stock UE4’s streaming system — further confirming the engine has been substantially modified beyond a standard integration. Its documented behavior (controlling retention vs. load priority separately, with game-specific tradeoffs for different asset types) is consistent with a custom streaming pipeline built on top of the base UE4 framework.
Where direct evidence is unavailable, claims are labeled as inferred.
Contributions & Corrections
This analysis is a living document. If you have additional profiling data, counter-evidence, corrections to technical claims, or insights that improve the accuracy of anything written here — I genuinely want to hear it.
All contributions that hold up to scrutiny will be incorporated into the article, and contributors will be credited by name (or handle) directly in the relevant section. The most up-to-date version of this article is maintained on GitHub — if you want to suggest a correction or addition, you can open an issue or reach out directly.
The goal isn’t to be right. The goal is for the best available explanation to exist somewhere people can find it.
Changelog
2026-04-21
- Added community-sourced findings from @HtooMyatLin3:
- FP16 cross-platform constraint: GTX-series FP16 throughput runs at 1:64 vs FP32 ratio — hardware-level reason why FP16 shader optimization cannot ship without dropping GTX support first (Section 5 — FP32 cross-platform constraint)
r.ParallelFrustumCullandr.ParallelOcclusionCullconfirmed functional in WuWa’s shipping build — culling pipeline is not entirely GameThread-serialized (Section 5 — causal attribution note)r.Streaming.FullyLoadUsedTexturesandr.Streaming.HLODStrategywere usable in older patches but are now locked by Kuro at higher priority via code/console, confirmed through log analysis — Engine.ini entries no longer effective at runtime (Section 5 — The One Genuinely Easy Fix)r.Streaming.UsingKuroStreamingPriorityidentified as Kuro-specific cvar not present in stock UE4, additional evidence for customized engine build (Limitations)
- Added
r.ParallelFrustumCull/r.ParallelOcclusionCullfootnote to Section 5 causal attribution - Added
r.Streaming.UsingKuroStreamingPrioritynote to Limitations section